


 1389
1389
随着AI芯片算力需求爆发,摩尔定律逼近物理极限,单纯依靠工艺微缩已难以满足性能增长。国产EDA正迎来关键转折:从单点工具走向全链路系统级解决方案,以“系统思维”应对AI时代硬件设计的复杂挑战。
系统级设计成破局关键
在AI算力集群、Chiplet先进封装成为主流的今天,芯片设计已不再是单一环节的优化,而是贯穿“芯片-封装-板卡-系统”的整体协同。
对此,芯和半导体创始人兼总裁代文亮博士举例解释道:“工程师常会遇到类似的棘手问题,一颗在测试中表现优异的芯片,一旦经过封装,性能会显著恶化。究其根源,在于传统设计流程的割裂——芯片与封装被孤立地抽取模型,再机械地拼接。这种方法完全忽略了二者间复杂的耦合效应。”
“再以Blackwell 200为例,即便芯片本身乃至板卡设计都近乎完美,在集成到机柜系统时,依然可能遭遇性能瓶颈或故障。问题的根源在于,传统的设计视角未能充分考虑系统集成过程中必定会产生的信号、供电、散热等相互作用。因此,我们必须将分析边界从芯片和板卡,扩展至连接器、供电网络等整个系统链路。”
在此背景下,我们看到芯和半导体提出的“STCO”理念,正是对这一趋势的响应——从传统的“工艺驱动设计”转向“系统驱动设计”,覆盖电、热、力等多物理场耦合,实现从芯片到集群的全栈仿真与优化。
EDA for AI:从芯片到集群
面对AI硬件在Scale-Up与Scale-Out中的互连、供电、散热等系统级难题,国产EDA企业如芯和已布局三大平台:
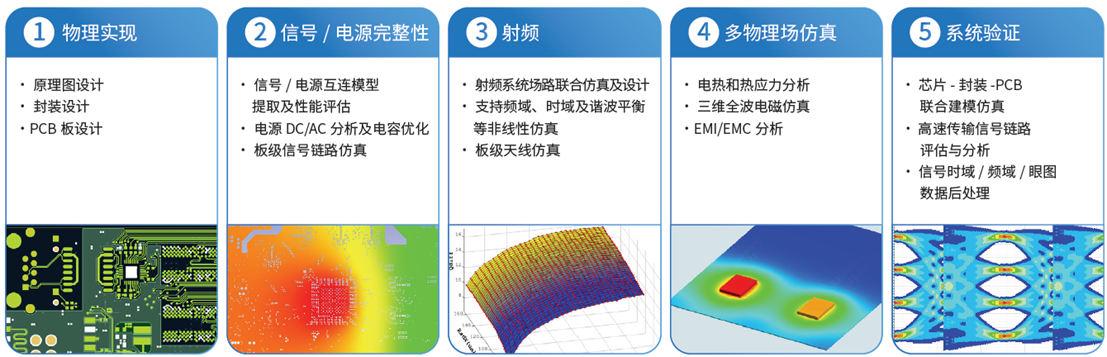
- Chiplet 先进封装设计平台:从芯片、Interposer 到封装的跨层级协同设计与多物理分析,面向“AI 芯片级”应用,解决多项互连、供电与散热挑战
| 互连
NVLink-C2C UCIe CXL 3.0 PCIe 6.0 HBM连接 CPO光电共封 |
散热
液冷板 均热板 局部微流道散热 热通孔 微型热管阵列
|
电源网络分配
3D-PDN三维电源地网络
|

| 封装/板级互连
NVLink 5.0 NVSwitch 4.0 UALink 1.0 800G Ethernet 灵衢协议 CXL 3.0 PCIe 6.0 224G SerDes |
光电通信互连:
CPO光电共封 CPO交换机 可插拔光模块 ? |
散热
冷板式液冷 浸没式液冷 风液混合散热 热管 均热板 ? |
电源网络分配:
高性能芯片大电流 高速芯片IO电源 大电流多相VRM 汇流条装配 ? |
 ?
?
- 集成系统仿真平台:提供电磁、热、应力、流体多物理场深度耦合求解引擎,实现高速通道端到端验证及整机柜集群级的横向扩展(Scale-out)
| 互连
Infiniband UALink 1.0 灵衢协议 800G Ethernet 硅光集群互连模块 CPO交换机 |
散热
CDU冷水机组 数据中心模块级浸没
|
电源网络分配:
高压直流母线 多板大电流汇流条装配 集中供电柜
|
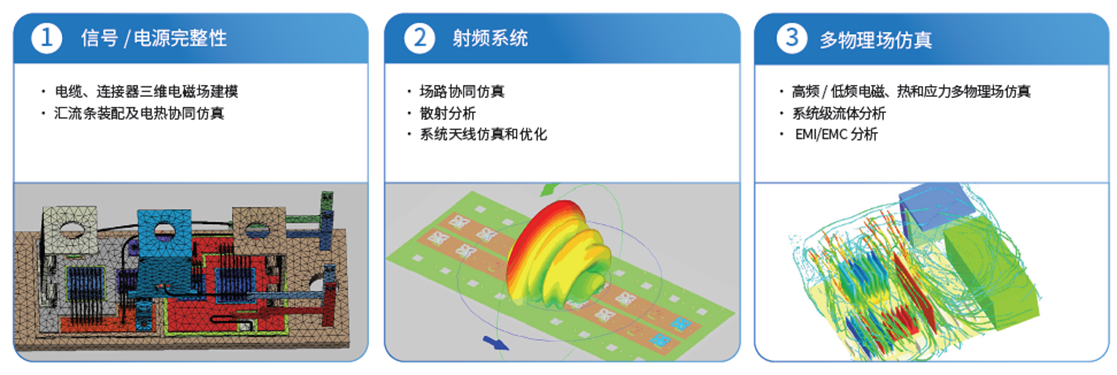
这些平台不仅服务于芯片公司,更面向整机厂商、数据中心运营商,体现出EDA从“辅助设计”向“系统赋能”的转变。
AI+EDA:技术重构与范式升级
“AI对我们而言不是营销口号,而是解决问题的核心底座。” ,代文亮博士表强调。
AI不仅加速仿真,更重构EDA工作流。芯和推出的XAI多智能体平台,将建模、仿真、交互、数据四大智能体融入设计流程,实现“仿真驱动设计”。工程师从“工具操作者”转变为“系统架构师”,设计效率提升数倍,仿真时间从天级缩短至秒级。
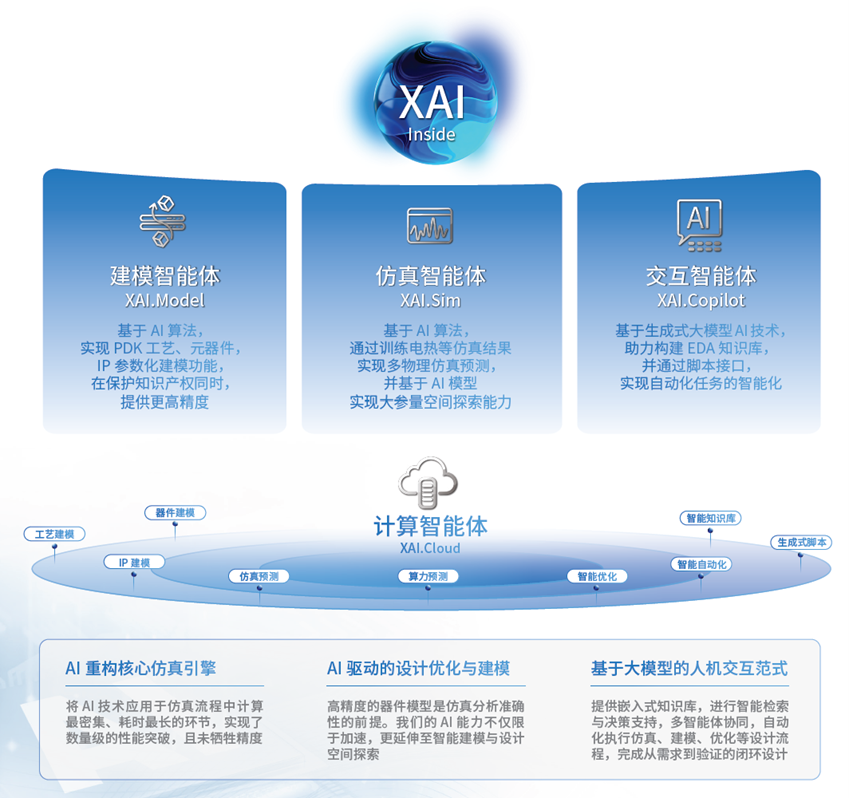
更重要的是,基于真实物理模型与多物理场耦合的AI训练数据,国产EDA能在精度与可靠性上逐步建立起自主优势,避免陷入“代际落后”。
对此,代文亮博士解释道:“我们利用经过第一性原理和严格物理方程验证的海量数据来训练AI模型,生成可靠的、无‘幻觉’的‘蒸馏数据’。这使得设计师能够将过去耗时数周的分析压缩到瞬间,实现‘秒级’仿真,且精度保持在5%以内,对于设计周期加速具有可观的红利效应。”
结语
国产EDA的下一步,不再是单点工具的替代,而是系统级能力的构建。在AI驱动下,从芯片到系统的全栈EDA能力,将成为中国半导体产业实现高水平科技自立自强的关键支撑。系统升级,不仅是技术路径,更是战略必需。
来源: 与非网,作者: 夏珍,原文链接: /article/1913405.html







