


 2506
2506
2023年,ChatGPT超级用户破亿仅用2周,这是2017年transformer出现后最激动人心的一年。但也就在这一年,后摩智能CEO吴强在自动驾驶赛道陷入困境。
“当时L3被质疑永不落地,2023年底,整个自动驾驶赛道变得非常卷,行业到处都在讲千元级的智能驾驶方案,我们当时近300Tops的芯片算力太超前、太冗余了”, 吴强坦言,“芯片和市场需求当时是有gap的。我们意识到这个赛道有可能走不通,因为行业格局逐渐稳定,给新入局的机会越来越少;如果我们再开一个新的芯片挤入,市场窗口就又错过了。”
AI大模型的端边觉醒——远离内卷,刚需市场“落子”
终于在2023年底。后摩智能全面转向端边大模型AI芯片的研发——这个被吴强称为“生存大于面子”的转型,其核心逻辑直击两大痛点:“云端训练,边端推理” 正在成为新范式,90%数据处理将在边缘和端侧完成;同时。端边AI具备 “更懂用户” 的潜力:响应快、数据无需上云、无风扇静音(如智能会议设备)。
“基于这些认知,我们决定聚焦在端边大模型的AI计算领域。2024年初,我们快速把第一代芯片调整了一版,推出第一颗面向大模型的存算一体AI芯片M30”,吴强说。
也正是这颗芯片,首先随中国移动在2024年MWC上运行60B大模型验证了可行性,也为最新推出的M50奠定了基础。“我们决定聚焦在端边大模型AI计算,让存算一体和AI大模型形成共振,释放更大的势能”,吴强强调。
在他看来,大模型产业当前正经历深刻变革,行业已进入"推理密度"与"能耗密度"双重敏感阶段,未来五年推理成本将占大模型全生命周期 80% 以上。在端边大模型部署“最后一公里”的竞争,或将成为决定未来产业格局的重要拐点。后摩智能的存算技术通过紧密集成存储和计算单元,不仅大幅提升了计算效率,还显著增强了内存访问速度,这对于处理大规模数据和复杂算法尤为重要。
“2023年下半年,我们做出调整后的战略聚焦——以存算一体技术为矛,直穿端边大模型计算的最后一公里,致力于成为端边大模型AI芯片领跑者”,吴强表示,“存算一体芯片自身能效比高——在同等功耗下,可实现更大的算力;或是同等算力下,能达到更低的功耗。这是它与AI大模型天然的契合点。”
存算一体端边大模型M50芯片,打破“不可能三角”
“发挥存算一体优势,放眼端边蓝海市场”——随着这一理念的清晰,后摩智能的产品也在稳步推进。

后摩智能创始人兼CEO吴强博士现场发布
就在WAIC 2025前夕,后摩智能正式发布了最新一代端边大模型 AI 芯片——后摩漫界M50,实现了160TOPS@INT8、100TFLOPS@bFP16的物理算力,搭配最大48GB内存与153.6GB/s的超高带宽,典型功耗仅10W,相当于手机快充的功率,能让PC、智能语音设备、机器人等智能移动终端运行1.5B到70B 参数的本地大模型,实现了“高算力、低功耗、即插即用”。
高算力、高带宽、低功耗——这三项看似互斥的指标,正是存算一体技术大显身手的主场,后摩智能从 2020 年就开始深耕这一领域。存算一体架构通过把计算和存储单元集成在一起,让数据就近处理,从根本上解决了传统芯片“数据传输慢、功耗高”的问题。
M50 芯片作为这项技术的集大成之作,宣称是市场上能效比最高的端边大模型AI芯片。其第二代SRAM-CIM双端口存算架构能让权重加载和矩阵计算同时进行,支持多精度混合运算,可兼顾模型部署的各项需求。

而之所以采用了20mm*23mm这样的小型化设计,吴强阐释核心在于精准匹配目标客户的成本承受区间与场景需求,功耗约束与成本控制共同决定了芯片的物理尺度。他同时强调,算力规模本质上是可配置的:“若有客户需要更大算力,只需增加芯片面积即可实现。事实上,已有客户因特定场景的功耗限制(如边缘设备散热瓶颈),提出‘高算力+低功耗’的定制需求。这类场景中,面积成本反而非首要制约因素。”
据了解,后摩的SRAM存算方案属于存内计算,是通过重构SRAM存储阵列的物理结构(而非直接采用标准SRAM单元),将计算单元嵌入存储矩阵。这与“近存计算”(在标准SRAM旁附加计算单元)存在本质差异。其一大突破在于SRAM存内计算以比特(bit) 为最小处理单元,该设计使数据可按比特粒度分步处理,最终聚合结果,该特性为弹性计算优化创造了基础条件。
除了高效的存算IP,如何能把它高效用起来,也很考验AI处理器或IPU的设计能力。“后摩第二代IPU架构“天璇”针对大模型计算特征实现双重优化:首先是通过自适应计算实现的弹性计算,提升了算力利用率,能够实现更快的运算效果;其次是业内首次在存算架构上量产浮点运算单元,通过直接部署FP16开源模型,免除了量化调参环节(仅特殊场景需额外优化),加强了芯片落地时的易用性。

此外还有新一代编译器后摩大道,可根据芯片架构自动选择最优算子,无需开发者手动尝试;支持浮点运算,无需量化参数和精度调优。和传统架构相比,M50 的能效提升 5~10 倍,完美适配了端边设备"算得快又吃得少"的需求。
从现场Demo演示来看,M50单芯片运行Qwen3-14B模型,5分钟生成1小时会议纪要(声纹识别+文本总结),以及运行Qwen2.5-7b模型面向信创市场的公文写作,都达到了良好效果。据了解,联想、科大讯飞、以及中国移动等,已成为主要的意向客户。

据吴强介绍,下一步重点的布局领域包括:平板和电脑等消费终端类,智能语音系统,以及运营商的5G+AI边缘计算。
“我们致力于构建更加完整的存算技术体系,一直在探索DRAM-PIM的产品化,它包括实现方式:一是on-die方案,就是在DRAM芯片中布局,放入更多的计算单元(下图左);二是3D-DRAM方案(下图右),通过堆迭的方式实现。这两种方式的成本和性能都完全不一样,适合非常不同的应用场景”,吴强透露,“预计明年会发布基于DRAM的存算一体芯片,这是我们过去两年在存算一体技术更加完整的技术体系的发展,以不断蓄积在该领域的优势。”
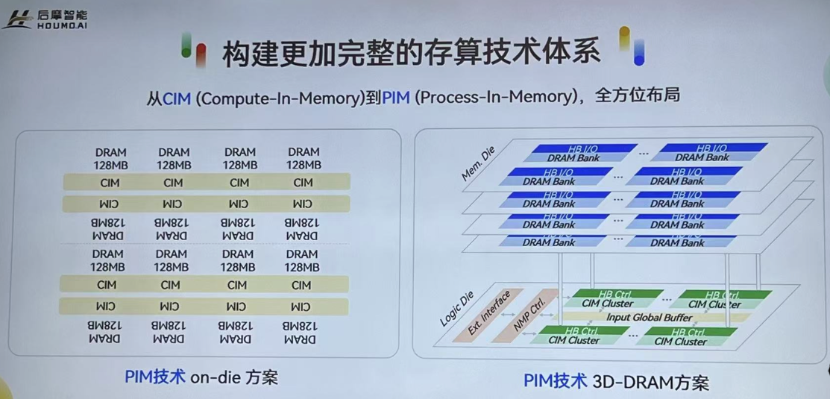
据介绍,后摩智能过去两年陆陆续续在国际顶刊发表了30多篇论文。其中和北京大学合作的一篇关于DRAM的存算用在大模型推理框架上的文章,刚刚入选今年ISCA最佳论文。“我们关注的是底层模型层面的新技术,能不能适配得更好。这也是为什么我们团队一直在写文章,我们是奔着最前沿的方向去的”,他补充。
覆盖端边多元场景,后摩智能的算力蓝海战术
除了 M50 芯片,后摩智能此次发布的产品矩阵形成了覆盖端侧到边缘的多元算力方案。

力擎LQ50 M.2卡以口香糖大小的标准 M.2 规格,为 AI PC、AI Stick、陪伴机器人等移动终端提供 "即插即用" 的端侧AI能力,支持7B/8B模型推理超25tokens/s;力擎LQ50 Duo M.2 卡集成双 M50 芯片,以 320TOPS 算力突破 14B/32B 大模型端侧部署瓶颈。

力谋LM5050 加速卡与力谋LM5070 加速卡分别集成 2 颗、4 颗 M50 芯片,为单机及超大模型推理提供高密度算力,最高达 640TOPS;BX50 计算盒子则以紧凑机身适配边缘场景,支持 32 路视频分析与本地大模型运行。
这些产品可广泛应用于消费终端、智能办公、智能工业等多元领域,且均能在离线状态下实现全流程本地处理,从源头杜绝数据联网传输风险。
除了对于数据隐私性的重视,端边市场对于成本、功耗格外敏感。“我的观点是不应该拼价格,拼的是性价比。只要能给客户创造价值,其实就有人愿意买单。比如高端智能手机,尽管售价不低,但仍有其独特的市场。我们也在和合作伙伴一起探寻,能在端边大模型市场找到客户认可的价值场景,最终促进产品大规模落地”,吴强表示。
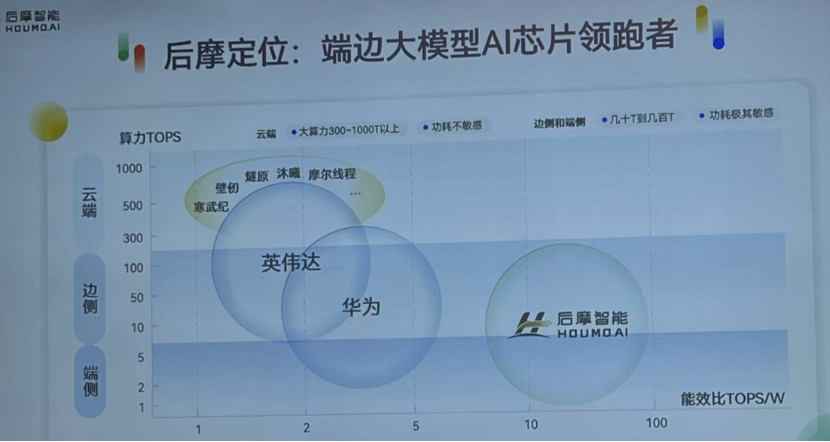
“未来大模型有两个重要趋势,一是逐渐从训练向推理迁移,二是逐渐从云端智能向端边智能迁移。未来的计算格局有可能是端、边、云的混合体,90%的数据处理可能会在端、边,只有10%的训练或复杂任务放在云端”,吴强强调,“相对于英伟达、华为等巨头的云边端通吃,或是新兴公司在云端GPU的激烈竞争,后摩智能希望成为端边大模型AI芯片的领跑者,通过更好的能效比,解决端边的实际问题,打造一个‘低功耗、高安全、好体验’的端边智能新生态,真正赋能千行百业。”
来源: 与非网,作者: 张慧娟,原文链接: /article/1868590.html


